

Introduction to ADX LipSync Tools
CRI ADX LipSync is a middleware that uses a unique combination of sound analysis and machine learning algorithms to automatically generate natural mouth patterns for animation. These patterns contain information about the opening of the mouth, and the position of the lips and the tongue. In this post, we examine how they can be generated by using the CriLipsMake tool.
CriLipsMake
CriLipsMake is a command line tool provided with CRI ADX LipSync that takes audio files containing speech and generates the corresponding mouth patterns in comma-delimited text files (.adxlip). There are many situations in which such an offline tool is required.
For instance, the results may need to be imported later into an animation tool – either 3D (e.g., Maya, 3DS Max, Blender) or 2D (e.g., SpriteStudio, Live 2D, Spine) to be used by artists to prototype and edit facial animations for their characters.
During game production, offline processes can also be used when pre-rendering cut-scenes, or in order to save CPU cycles during dialogue sequences (The downside in this case is that the mouth patterns must be generated again each time the dialogue is modified).
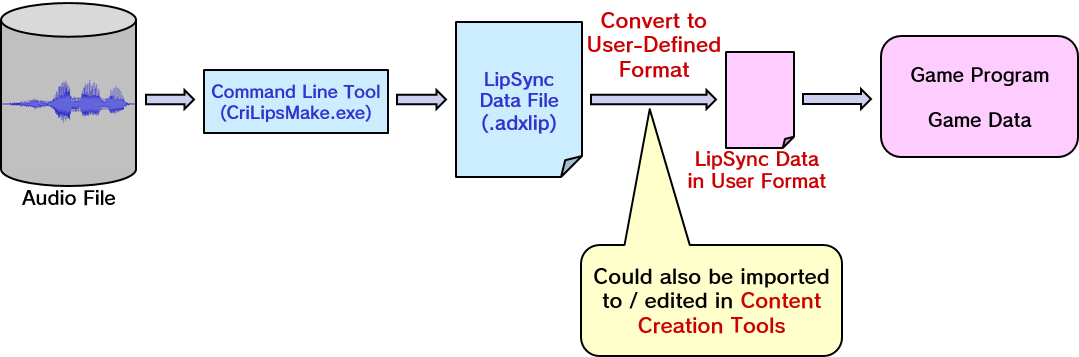
Generating mouth patterns
As any command line tool, it is recommended to add the path to the CriLipsMake executable as an environment variable, in order to access the tool from anywhere on your file system. After installing the tool, it can be found here: CRIWARE\Tools\ADXLipSync\CriLipsMake.exe.
The format of the audio data supported in input by the tool is:
- File Format: .wav or .aiff file.
- Sampling Rate: 16kHz to 96kHz.
- Bit depth: Signed 16/24/32 bit integer, signed 32 bit floating point.
- Number of channels: Files with any number of channels are accepted, but only the first channel will be analyzed.
From there, generating mouth patterns from an audio file can be done with one simple command:
CriLipsMake.exe in=“Audio_Voice.wav”This will output an .adxlip file with the same name than the audio file, and in the same folder. Note that if a file with the same path already exists, it will be overwritten.
The following arguments can be specified:
Required:
- -in [Input File(.wav/.aiff)] Path of the audio file to analyze.
> CriLipsMake.exe in=“.\Voice_Folder\Audio_Voice.wav”Optional:
- -out [Output File(.adxlip/.txt/.csv)] Path of the output file containing the mouth patterns (by default, the same directory and basename as the audio file).
> CriLipsMake.exe in=“Audio_Voice.wav” out=“.\Data\Mouth_Pattern.adxlip”- -fps [1 – 100] The frame rate of the mouth patterns returned by the analysis (Default: 60).
> CriLipsMake.exe in=“Audio_Voice.wav” out=“Mouth_Pattern.adxlip” fps=30- -volthreshold [-92 – 0] The volume threshold used for the detection of silence (Default: -40).
> CriLipsMake.exe in=“Audio_Voice.wav” out=“Mouth_Pattern.adxlip” fps=30 -volthreshold=-35.0To process multiple files, simply write a batch script. Here is a simple example that will generate the mouth patterns for every .wav file located in the current folder:
> @echo off
> for /R %%G in (*.wav) do (
> call CriLipsMake.exe -in="%%G" -out="%%~nG_-30thld.adxlip" -volthreshold=-30)
Usage of the mouth patterns
The resulting .adxlip file is a comma-delimited text file, easy to handle, convert, and import in any other software.
The data returned by ADX LipSync can be used to create lip sync animations and is described below:
- frame count: the current analysis frame (updated according to the frame rate).
- msec: the time of the current frame in milliseconds.
- width, height, tongue position: these values correspond to the mouth width, mouth height and tongue position, respectively.
- A, I, U, E, O: contribution amounts of the Japanese A, I, U, E, O vowels to the shape of the mouth (hereafter called blending).
- Vol: the volume of the audio in dB. It can be used as a reference to make adjustments, for example to open the mouth wider when the volume is high.
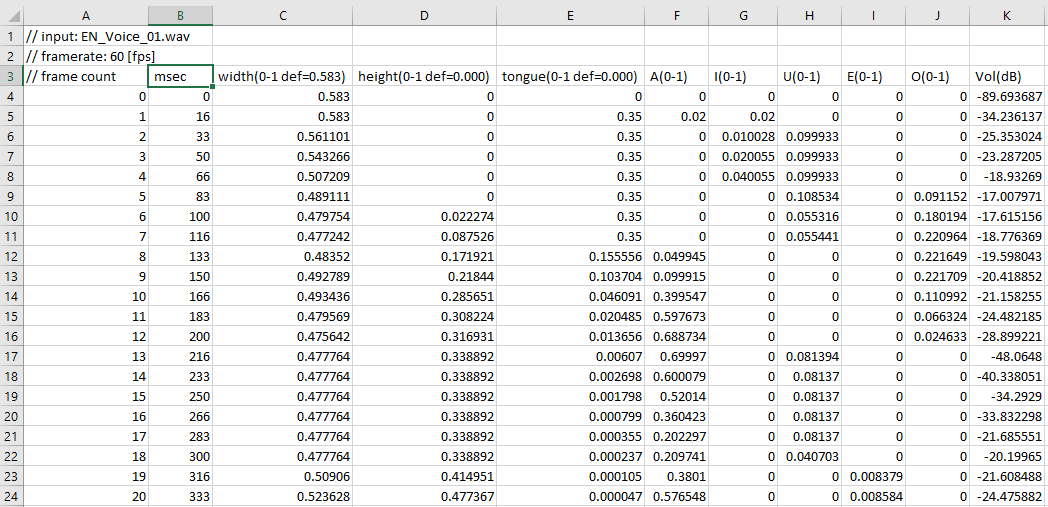
ADX LipSync’s analysis therefore outputs two types of data for mouth patterns:
- One is the direct mouth shape data, based on the height, width, and tongue position.
- The other is the mouth shape data based on a blending of the A,I,U,E,O Japanese vowels.
The Japanese vowels data itself can be applied directly on five blend shapes corresponding to the five vowels A,I,U,E,O. Combining shapes makes it possible to create natural expressions for non-Japanese sounds.
Both types of data can also be combined, for example using the direct mouth shape data to control the width and height of the mouth shapes returned by the blending of the Japanese vowels, leading to more detailed expressions.
In both cases, by controlling the tongue separately, more realistic character expressions are achievable.
By using high-quality and easy-to-use mouth patterns based on the ADX LipSync analysis technology, artists can create high-quality animations at a lower cost!